DigitalOwl has dedicated years to meticulously analyzing medical documents, distilling insights from them and summarizing the information for easier consumption. Now, we're opening up that data and making it directly and easily integratable with our new DigitalOwl medical data standard.
With our new API, companies can seamlessly integrate the extracted medical data into their own processes, enabling them to make faster, more accurate decisions. By leveraging our technology, providers can reduce claim processing times and improve the overall efficiency of their operations.
Why did we create (yet) another medical standard?
FHIR and CDA are widely used for exchanging health information, but they fall short when it comes to providing a comprehensive longitudinal patient medical history. FHIR focuses on exchanging discrete data elements, while CDA is designed for exchanging individual clinical documents such as lab results or discharge summaries. However, in order to have a comprehensive understanding of a patient's health, we need a standard that focuses on the patient rather than individual data elements or specific documents.
Here are some limitations of the FHIR/CDA standards:
-
The standards do not accommodate certain types of information, such as negated conditions, which are not supported.
-
No direct method to link the information to the actual source evidence, up to the exact wording that was used in the source page. This limitation makes it difficult to verify the accuracy and validity of the information.
-
No room in the standards for synthesized medical information and insights beyond the raw discrete data elements. This means that while the standard can exchange individual pieces of information, it cannot provide a comprehensive analysis of a patient's health status, which is critical for making informed decisions. For instance, exchanging a simple timeline of a patient's meaningful impairments is not possible with FHIR/CDA. Instead, hundreds or even thousands of condition resources are sent, putting the almost impossible task of interpreting that data on the receiving end.
-
The standards does not enable associating context to the medical information. Without context, it becomes challenging to understand the significance of the information, for example the details of the accident that caused a patient's impairments.
TL;DR
FHIR/CDA are awesome for storing and exchanging raw medical data, but very limited in understanding or driving insights from it.
Our Philosophy
Our philosophy in developing the data standard is rooted in the belief that on one hand, a comprehensive and holistic understanding of a patient's medical history is key, while on the other hand, black boxes are unacceptable in health, and every medical item should be linked to its source of truth. To achieve this understanding, we approach the problem like a skilled detective, piecing together information from multiple sources to form a complete picture. Our AI technology sorts through pages of scanned documents, EHR files, and charts, collecting and organizing discrete medical data into meaningful medical information and insights.
As the foundations for these capabilities, we use the following proprietary technologies:
- State-of-the-art medical entity extractions model which supports all formats, from scanned documents to EHR.
- Our Medical Knowledge Base (MKB) which normalizes, codes and enriches the medical extraction with indispensable medical and business information.
- AI which looks at all the mentions as a whole and distills usable and actionable medical information.
- Generative models which add the context and narrative.
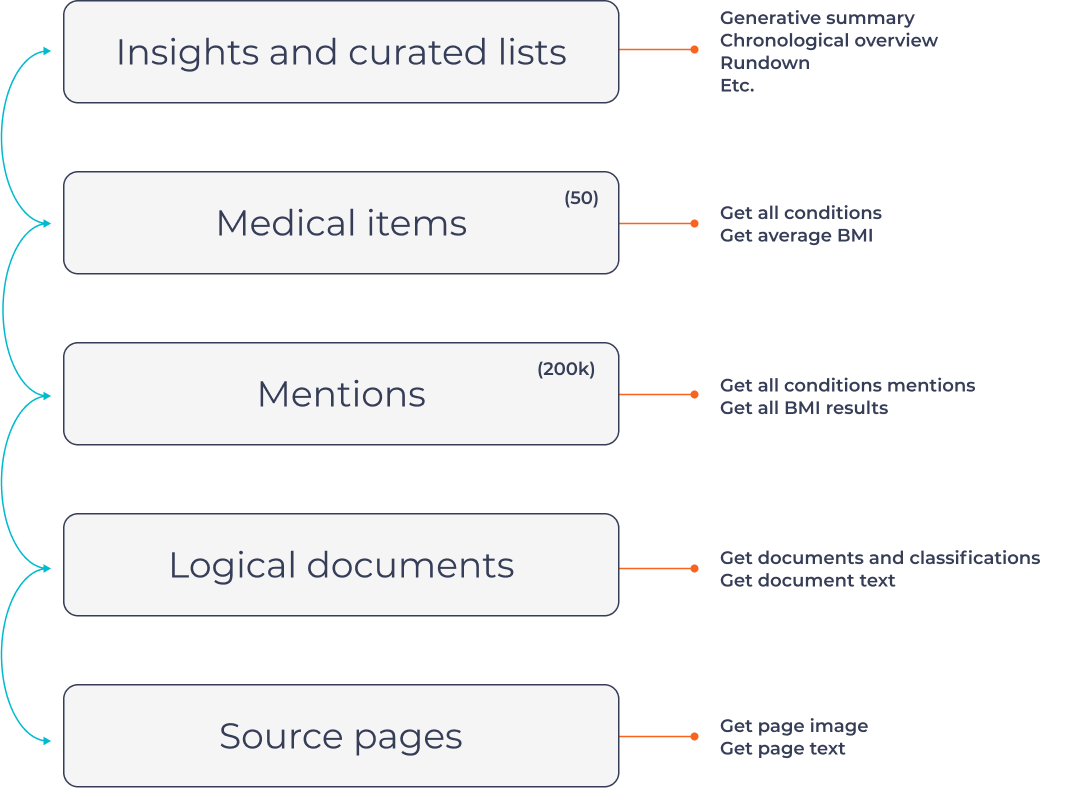
The data standard maps the above process into layers with associated APIs:
-
Source Data: Source Data: This includes the scanned documents and EHR files, including the source image and the OCRed text. For more info, see the Get Page Ids, Get Page Metadata, Get Page text and Get Page Image
-
Logical Documents: The pages in the digested PDFs are separated into different logical documents, such as doctor visits or hospital reports. For more info, see Get Case Documents and Get Document Text
-
Mentions: All mentions of medical conditions, procedures, medications and more, are aggregated from all sources, normalized, coded and enriched with proprietary information. Each mention can be traced back to its original page and contains the exact wording and a quote for a quick reference. Mentions can be fetch ethier by id Get Medical Mention, Page Get Page Medical Mentions.
-
Medical Items: A typical case can have hundreds of thousands of medical mentions. While medical mentions are useful for tracing back medical issues to a source page, they are difficult to distill insights from. Here, we synthesize mentions into useful medical items. For example, the countless mentions of hypertension across many years and visits from different data sources, each with different wording, are merged into one useful medical item. All A1C values, scattered across many pages, are collected into one medical item with useful stats of the A1C trend. For more info, see Get medical items API
-
Generative Text: The context and narrative of the case are important and cannot always be represented using coded extractions. Therefore, we dedicated a place in the standard for multiple generative summaries, Q&A, etc. For more info, see Get Generative by Id
-
Insights and analysis: We also identify red flags and other noteworthy information to give a comprehensive overview of a patient's health history.